Naver Boostcamp AI Tech 7기 Week 5 회고록
Naver Boostcamp AI Tech 7기 Week5 회고록
2024-09-02 회고
오늘 피어세션에서는, Prompt Engineering과 Attention is not Explanation 논문에 대한 이야기를 했었다.
사실 Attention is not Explanation 논문 자체는 이전에 졸업논문할때 읽어보려다가 말았던 논문이었다.
이번 피어세션에도 제대로 읽지는 못했다.. BERT를 읽고 그 후에 한번 쓱 읽어봐야겠다.
K
Prompting을 매번 알아볼까 알아볼까 하면서 미뤘었는데, 이번 기회에 공부를 한 것
코어시간에 졸지 않은 것..
P
- 피어세션 이후에 조금 많이 쉬어버림. 적당히 쉬고 다시 공부에 집중하자.
- 강의를 단순히 적는 것보다 이해하는 것이 중요
T
- 해볼만한 사이드프로젝트를 고민해보자
2024-09-03 회고
오늘 멘토링에서 Git Flow에 대해서 말씀해주셨다. 회고는 복습으로 하자.
사실 Git Flow 자체는 유명하다.
어떤 툴이라기보단 하나의 방법론을 말하며, 여러회사에서도 사용하고 있다.
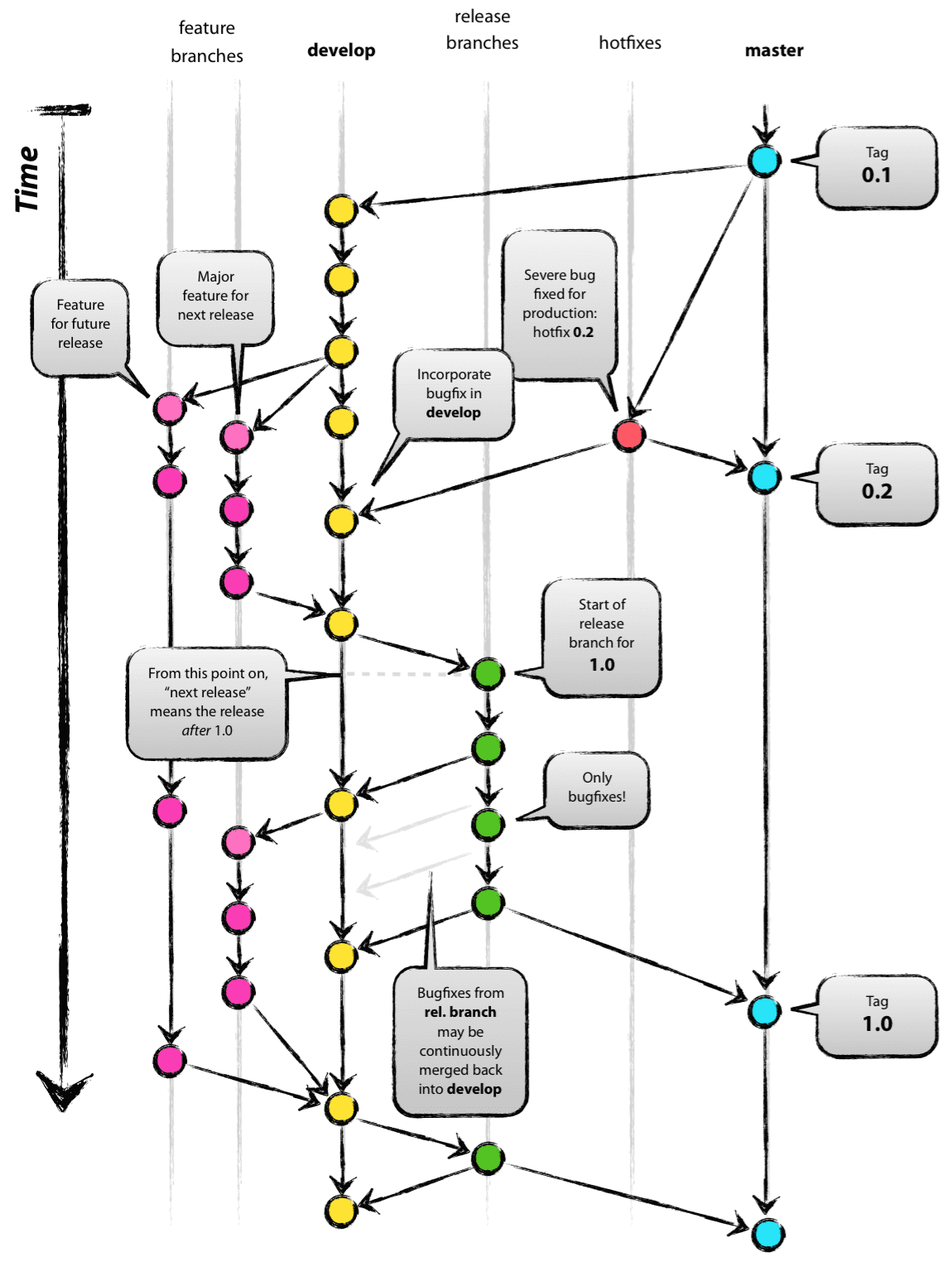
Main 브랜치, Develop 브랜치, Feature 브랜치, Release 브랜치, Hotfix 브랜치로 나눠서 작업을 한다.
Main 브랜치는 서비스를 배포하는 역할을 하기에 무조건, 쉽게 Merge를 해선 안되고 PR로 잘 점검해야한다.
그래서 실제 개발할 때에는 Develop 브랜치를 새로 파서하는데, 이것도 혼동을 위해 Feature 브랜치를 따로 더 파서 개발 후 Develop에 병합시키는 것을 목적으로 한다.
여기서 Commit 할때 중요한 것은 “작은 단위”로 커밋하는 것을 중점으로 둔다. 작은 단위라는 것은 주관적이지만,
실제 문제가 발생해도 롤백하기가 쉽다.
Release 브랜치의 경우 있어도되고 없어도되는 브랜치인데, 보통 QA가 Main에 올리기 전 마지막 버그점검하는 상태를 의미한다. 그리고 버그가 생기면 다시 Develop 브랜치에서 Feature로 빼서 버그 수정하고 다시 Release하고.. 이렇게 반복
Hotfix는 말그대로 Release에서 QA가 발견하지 못한 버그를 Main에서 발생하게 되면 실제 서비스하는 브랜치이기 때문에 빠르게 버그를 수정해야한다. 그래서 Hotfix에서 빠르게 처리 후 Main버전에 PR한다.
생각보다 어려운 개념은 아니다. 하지만 여러명이서 작업하고 PR하는 과정에 Merge를 잘못하면 꼬일 것 같다는 생각이 들었다.
추가로 Commit Rule도 중요하다, 팀원 간 commit rule를 안맞추면.. 백업할 때의 어려움, 버그났을 때 등등 어려움이 있기에 필수로 맞추자.
멘토님께서 추천해주신 방법이 있어서 그 방법으로 사용해보자.
추가로 정리해야할 것
- Rebase, 체리픽?
2024-09-05
K
- Shape를 맞춰가는 과정에 대해서 다시 한번 짜릿함을 느꼈다. 수식을 보고 구현하는 방법에 조금 익숙해져가는 모습이 뿌듯하다.
- 강의를 이해하느라 조금 과제가 늦어졌는데, BPE과정을 직접 제대로 구현해본 것이 뿌듯함을 느꼈다.
P
- 하지만 이번 과제를 구현하면서 GPT힘을 빌린 것이 아쉬웠다. 나름 수식을 보고 해결할 수 있을 것이라도 느꼈었는데, 아직 부족한가보다.
- GPT에서 나온 코드들을 이해하지않고 그냥 사용하고 마는 것이 아쉽게 된다. 따로 정리하자.
T
- 코드에 대해서 짜기 어렴움을 느낄 때 최후의 최후까지 생각하다가 GPT에게 물어보는 것, 그리고 그것을 제대로 정리하는 것
torch.bmm : torch.matmul과 비슷하나, bmm의 경우 차원에 좀 더 제한을 거는 것
concat attention, dot product attention 차이에 대해서 알아보기
concat -> dot product 순으로 생겨남
- RNN을 수행하기 전 이전 Hidden state를 보는 것 (concat)
- 즉 RNN을 시행하기 전 Attention을 미리 넣는 것
- 현재 time step의 Hidden representation을 참조하는 것
- 간단하게 둘의 차이점은 “시점”의 차이라고 본다.
- 이전의 Hidden representation의 Attention을 포함시킨 후 RNN을 돌리는 것
- RNN을 돌린 후 현재의 Hidden representation의 Attention을 계산하는 것
2024-09-06
최근 sLLM에 대해서 관심이 가지게되서 여러가지 sLLM 방법론에 대해서 알아보았었는데, 결국은? 최적화가 가장 큰 관점이다.
Pruning, Knowledge Distillation, Quantization 등..
이 3가지 부분에 대해서는 더 공부해보자, 나는 가장 주의깊게 보는 부분은 Knowledge Distillation 파트이다.
