Naver Boostcamp AI Tech 7기 Week 7 회고록
Naver Boostcamp AI Tech 7기 Week7 회고록
2024-09-23
오랜만에 쓰는 회고록이다.
프로젝트를 계속 진행하고 있지만, 뭔가 아쉬운 느낌이 든다.
특히 “시간이 조금만 더 있었으면..” 하는 마음이 있다. 그러다보니 마음이 조급해지고.. 계속 허탕치는 느낌이 든다.
마음을 다시 잡고 26일까지 최대한 마무리 짓고싶다.
사실상 Baseline Code에서 다른사람들이 Wandb, Optuna 등 다른 부분들을 채워주어서 덕분에 다른 부분에 집중할 수 있었다.
하지만 KR-SBERT는 아무리해도 잘 되지않았다… 추후에 다시한번 해보고싶다.
근데 할 시간이 있을까..? 바로 프로젝트 또 시작이던데.. 흠
아무튼 오늘부터 모델 고도화 파트에 들어갔다.
프로젝트를 진행하면서 조금 아쉬운 부분인데, 모델 고도화 부분에 빠르게 들어가지 못한 점이 아쉽다.
아무래도 Model selection하는 기간이 너무 길었던게 일정이 빠듯해진 이유인 것 같다.
하지만 다른것들을 원없이 테스트해본 것이 좋았다..
현재 나는 Data Augmentation Part를 맡아서 진행하고있다.
크게 3가지로 찾아보았는데, 다음과 같이 정리되었다.
- Back Translation
- EDA (Easy Data Augmentation)
- BERT-Augmentation
Back translation의 경우 번역 -> 재번역하는 과정인데, 어순이나 어법이 좀 비슷한 일본어가 성능이 잘 나올 것으로 생각되어 시도해보았다.
EDA의 경우 코드만 찾아두고 팀원께 부탁드렸다.
2024-09-24
각 Augmentation한 테스트 결과를 보았는데, 생각보다 좋지 않았다.. 나름 augmentation하면 괜찮을 줄 알았는데, 아니었던 것이다.
아무래도 모든 Augmentation을 적용하는 것은 더 성능이 떨어질 것 같았다. 왜냐하면 BERT모델 특성 상 중복된 데이터가 많으면 많을수록 성능이 떨어지는 것이었기 때문이다.
우선 Augmentation한 데이터들에서 하나하나씩 방법들을 빼면서.. DeBERTa 모델에 학습한 결과를 살펴보기로 했다.
근데 이것만해도 생각보다 꽤 많은 데이터를 학습해야했기에 1에폭당 15분이 걸리는 문제가 있었다… 최소 모델의 성능을 확인하기 위해선 10 에폭을 돌려야되는데… 거진 150분이 걸리는 것이다..
원래라면 하이퍼파라미터 튜닝도 같이 진행을 해야하는데, 할 수가 없었다.
그렇게 나온 결과로는 생각보다 좋지 않았다.
오히려 기존보다 0.02 그 이상 떨어지는 결과를 보였고 Augmentation 방법을 실패한 것으로 판단했다.
2024-09-25
프로젝트 마감 D-1…
우선 Augmentation이 제대로 안된다는 것을 파악했지만, 팀원분 한분께서 GPT4o로 데이터를 증강해서 한번 더 테스트해보기로 했다.
확실히 GPT에 프롬프팅해서 데이터를 주니 확실히 더 좋은 품질의 데이터를 얻을 수 있었다. 다만…. 양이 조금 많았다..ㅋㅋ 우리의 현재 데이터가 9300개 가량되는데, 생성한 데이터는 약 14000개 가까이 되었다.. 심지어 0.0 label을 제외한 데이터였음에도 불구하고 많이 생성되었다.
그래서 팀원과 상의 후 Generation하는 데이터를 최대한 줄이는 것을 목표로 했다.
따라서 BERT-Augmentation, Back Translation, GPT-Augmentation 중 가장 유의미한 문장을 만들어내는 GPT-Augmentation과 Swap Sentence 만들 사용하여 Augmentation Dataset을 구성하였다.
그후 테스트를 진행하였는데, 생각보다.. 성능은 좋지 않았다.
| Not Preprocessing | Preprocessing | Norm(0~1)(prep data) | Gpt4o augmentation + Swap Sentence (prep data) | Gpt4o Augmentation | Swap Sentence |
|---|---|---|---|---|---|
| val: 0.9291 test: 0.9190 | val: 0.9284 test: 0.9207 | val: 0.9270 test: 0.9177 | val : 0.9272 test : 0.9132 | val : 0.9262 test : X | val : 0.9286 test : 0.9148 |
그리고 데이터의 분포는 다음과 같다.
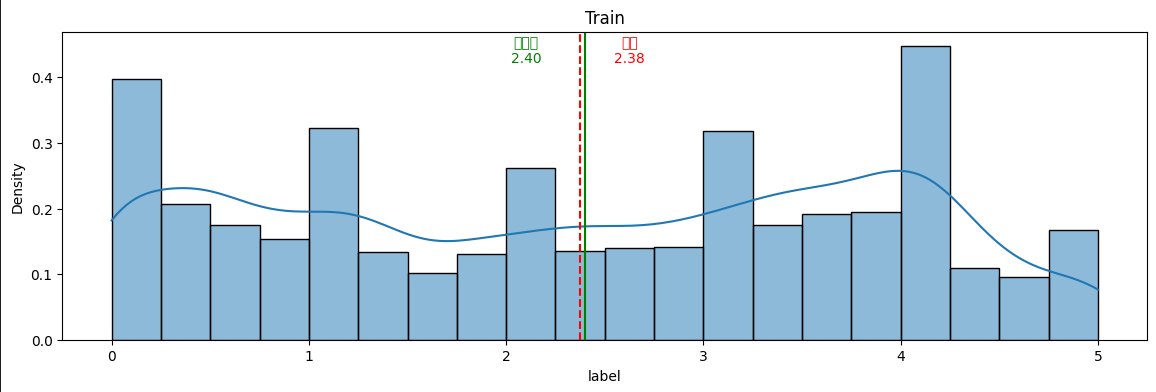
실패요인분석..
게시판에서 그런글을 보았다. “과연 데이터는 많으면 많을수록 좋은 것인가?”
그것은 아니다. 이때에는 데이터의 상태를 살펴보아야하는 것이 중요하다.
특히 BERT 계열의 모델의 경우 중복된 데이터가 많으면 많을수록 오히려 모델의 성능을 내지 못한다는 이야기가 있다.
아무래도 기존의 데이터를 유의어만 바꿔서 하다보니 더 성능이 떨어지는것으로 판단했다.
2024-09-26
대회 마지막날!!!
대회 마지막날이어서 우리는 Ensemble 모델을 시도했다.
기존 가장 최고성능이었던 DeBERTa와 새로 당일날 학습시킨 ELECTRA 모델 2개, RoBERTa를 기반으로 모델 Ensemble을 시도했다.
Stacking 기법이랑 Soft Voting중 가장 좋은 성능을 제출하기로 했다.
그 중 Soft Voting이 0.9376 Valid Pearson이라는 성과를 내었고.. 결과는!! 중간순위 15/16등.. 최종순위 10/16등을 하였다..!
그래도 우리 팀은 정말 하고 싶었던 것들을 다 하였다.. 다만 아쉬운 점은 “기록”을 못했다는 것이다.
